Scraping an Instagram public profile
Because they won't give you your data that easily

Working as of Nov 2020
I had troubles getting Instagram data for a project to help a restaurant engage more with their patrons. A lot of the tutorials on the web is outdated, so I wrote my own here.
I deployed the script as a microservice on AWS Lambda to send a regular report by email to me. The code can be found here. If you only want to scrape to a csv file, you only need the instaScraper.py file.
This post explains how to find the information required to run the code.
Can’t I just scrape the page source?
You can. The problem is the infinite scroll feature.
When you open an Instagram profile page, you get 12 posts by default, then you have to scroll down to load new ones. This process returns the new posts via Javascript and won’t update the page source, so you will only end up with the original 12 posts from the page source.
This also rules out using Selenium to do the scrolling for you (yeah I tried that), as the page source still won’t contain new posts.
Here’s how to get around that.
Getting all those ID’s!
Instagram uses graphQL API for profile pages. The following does not apply to a hashtag page as it uses a different query structure.
To get the query structure, open a public profile page (I use Firefox). Right-click and select Inspect.
Next, select Network, you will find a list of queries that were sent to the Instagram’s server. Scroll on the profile page to retrieve the next 12 posts while keeping the Network window open.
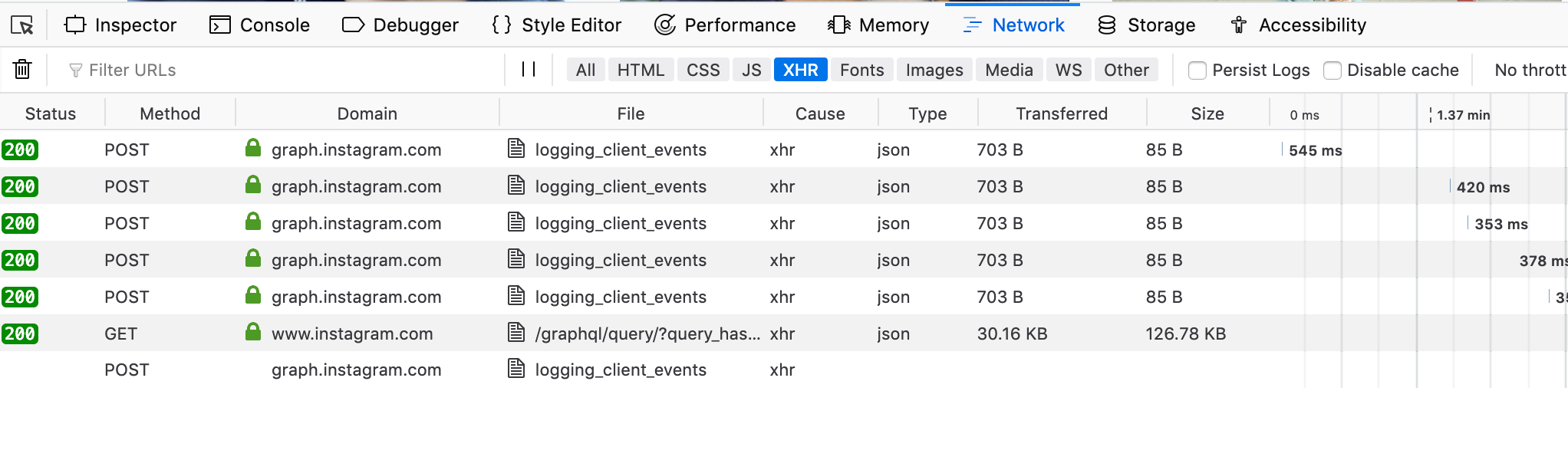
You should see a new GET query now. Click on that to open a new window.
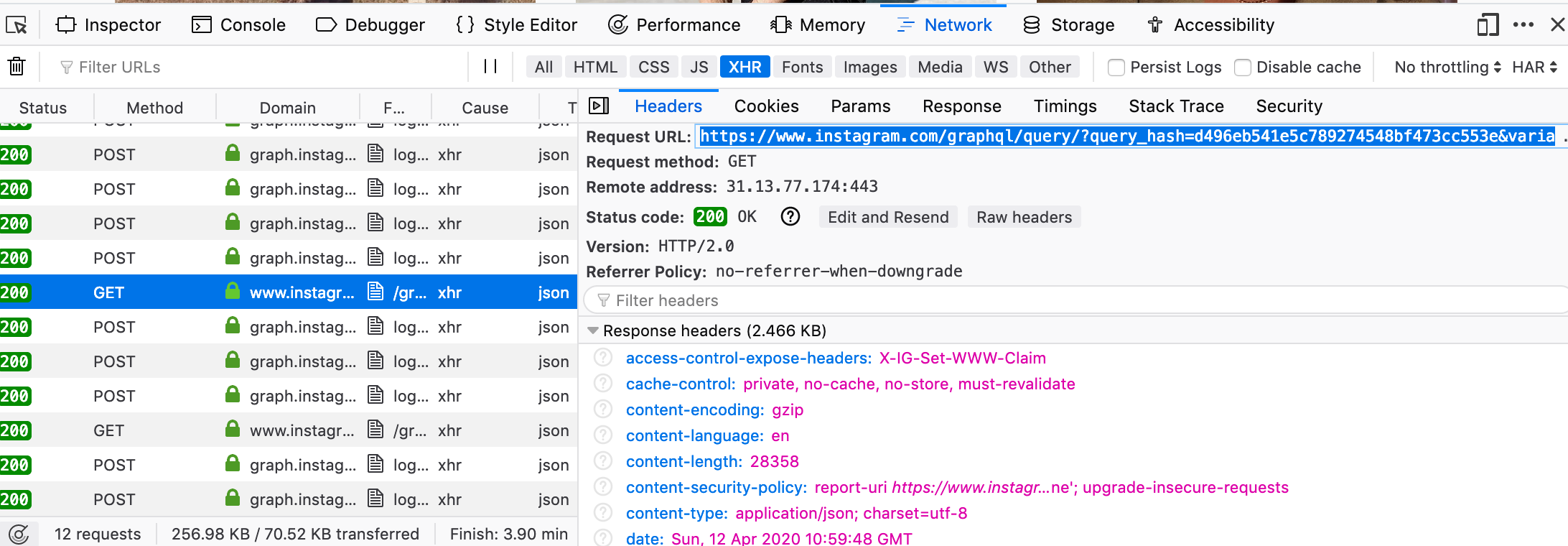
Click on XHR, and copy the “Request URL”. If you paste this to your browser, you will receive the raw response from Instagram, you can explore the JSON structure here to identify where the data you want is stored.
Let’s inspect the query string.
https://www.instagram.com/graphql/query/?query_hash=d496eb541e5c7892ezcaee&
variables={"id":"25025320","first":12,
"after":"QVFFUMmlKZDVreUJmlKZDVremlKZDVreKNmpJNA=="}
There are a few important parameters here:
- query_hash (d496eb…): for an explanation, read here. We need this!
- id (25025320): a unique identifier for the profile page you’re querying. We need this too.
- first: the number of posts to retrieve next, default to 12.
- after: an identifier for the last post in the previous query, i.e. post number 12 when you first open the profile page. It tells Instagram to find the next posts after that post ID. We don’t need this, but it’s nice to know.
- You also need the name of the Instagram page (like ‘apple’, ‘microsoft’ etc.)
Those are all the elements you need to provide the Python script to scrape the data. My script takes these ID’s from a params.JSON file formated like below. You can simply hard code it if you only scrape one page.
This is what I would use to extract post information from Instagram Instagram (heh!).
{
"user": "instagram",
"user_id": "25025320" ,
"query_hash": "56a7068fea504063273cc2120ffd54f3"
}
You can simply override the part where I read the JSON file with hardcoded ID’s.
Change from:
with open('params.JSON') as json_file:
params = json.load(json_file)
user = params['user']
user_id = params['user_id']
query_hash = params['query_hash']
To:
user = "instagram"
user_id = "25025320"
query_hash = "56a7068fea504063273cc2120ffd54f3"
The provided script extracts the post URL, description, likes and date. This helped me get all the data to analyse patterns in user interactions, useful hashtags, etc.
I complemplated explaining more how the script work, but most of it is really dealing with the data format of Instagram. I think it’s best to leave it for the readers to explore themselves.
Leave a comment if you find it useful/have any suggestions!